library(tidyverse)
library(stringr)
library(plotly)
library(scales)
library(corrplot)
library(ggcorrplot)
dataset<-read.csv("world-data-2023.csv")1st Attempt at Analysing World Data
R
Data Analysis
World Data Analysis
Here is another attempt at me trying to practice and get used to using R. I chose this one for a few reasons: One, I do have a passing interest in economics and development. As a Jamaican from a so called third world country/developing state, one of my big wishes is to see Jamaica and other Caribbean nations “develop” in a way that helps the citizens live better lives.
Additionally, depending on what we find in this dataset on countries around the world in 2023, I figure there may be some good insights to be gained. So its time to explore and see what we find.
Let’s begin by importing the data:
Now that the data has been imported, I’ll have a little look to see what I’m working with.
glimpse(dataset)Rows: 195
Columns: 35
$ Country <chr> "Afghanistan", "Albania", "A…
$ Density..P.Km2. <chr> "60", "105", "18", "164", "2…
$ Abbreviation <chr> "AF", "AL", "DZ", "AD", "AO"…
$ Agricultural.Land.... <chr> "58.10%", "43.10%", "17.40%"…
$ Land.Area.Km2. <chr> "652,230", "28,748", "2,381,…
$ Armed.Forces.size <chr> "323,000", "9,000", "317,000…
$ Birth.Rate <dbl> 32.49, 11.78, 24.28, 7.20, 4…
$ Calling.Code <int> 93, 355, 213, 376, 244, 1, 5…
$ Capital.Major.City <chr> "Kabul", "Tirana", "Algiers"…
$ Co2.Emissions <chr> "8,672", "4,536", "150,006",…
$ CPI <chr> "149.9", "119.05", "151.36",…
$ CPI.Change.... <chr> "2.30%", "1.40%", "2.00%", "…
$ Currency.Code <chr> "AFN", "ALL", "DZD", "EUR", …
$ Fertility.Rate <dbl> 4.47, 1.62, 3.02, 1.27, 5.52…
$ Forested.Area.... <chr> "2.10%", "28.10%", "0.80%", …
$ Gasoline.Price <chr> "$0.70 ", "$1.36 ", "$0.28 "…
$ GDP <chr> "$19,101,353,833 ", "$15,278…
$ Gross.primary.education.enrollment.... <chr> "104.00%", "107.00%", "109.9…
$ Gross.tertiary.education.enrollment.... <chr> "9.70%", "55.00%", "51.40%",…
$ Infant.mortality <dbl> 47.9, 7.8, 20.1, 2.7, 51.6, …
$ Largest.city <chr> "Kabul", "Tirana", "Algiers"…
$ Life.expectancy <dbl> 64.5, 78.5, 76.7, NA, 60.8, …
$ Maternal.mortality.ratio <int> 638, 15, 112, NA, 241, 42, 3…
$ Minimum.wage <chr> "$0.43 ", "$1.12 ", "$0.95 "…
$ Official.language <chr> "Pashto", "Albanian", "Arabi…
$ Out.of.pocket.health.expenditure <chr> "78.40%", "56.90%", "28.10%"…
$ Physicians.per.thousand <dbl> 0.28, 1.20, 1.72, 3.33, 0.21…
$ Population <chr> "38,041,754", "2,854,191", "…
$ Population..Labor.force.participation.... <chr> "48.90%", "55.70%", "41.20%"…
$ Tax.revenue.... <chr> "9.30%", "18.60%", "37.20%",…
$ Total.tax.rate <chr> "71.40%", "36.60%", "66.10%"…
$ Unemployment.rate <chr> "11.12%", "12.33%", "11.70%"…
$ Urban_population <chr> "9,797,273", "1,747,593", "3…
$ Latitude <dbl> 33.939110, 41.153332, 28.033…
$ Longitude <dbl> 67.709953, 20.168331, 1.6596…This shows a great deal. In this dataset, there are 195 rows or records. Each one represents an individual country. There are also 35 columns or fields. Each field represents a specific observation. The function in R also gives me the names and data types of these fields. Lots of the fields appear to be country demographics and general information. There’s a lot to be judged here.
And from this I can see the first issue. A lot of these fields that I would expect to be numbers are formatted as characters or text. Its not an impossible problem to fix, but if it’s not dealt with, it will make doing any analysis annoying at best and impossible at worst.
Re-formatting
Cleaning 35 columns now, saves me a lot of heartache in the future. I won’t show it all but here are some examples of how I could do that.
dataset<- dataset |> mutate (GDP = GDP |> str_remove_all("[$,]") |> as.numeric())
dataset$Density..P.Km2.<-as.numeric(dataset$Density..P.Km2.)Thankfully, there are more efficient ways to work
c.names<-colnames(dataset)
cols.to.format<-c.names[-c(1,3, 9, 13, 21, 25)]
cols.that.can.stay<-c.names[c(1,3, 9, 13, 21, 25)]
dataset<-dataset |>
mutate(across(.cols = cols.to.format,.fns = ~str_remove_all(.x, "[$,%]")|>
as.numeric()))What I’ve done above is to convert all the relevant character or text fields/columns into numbers so I can work with them.
What Do We want to know?
Now comes the brainstorming. There’s a lot of data here. A lot of the questions that come to mind have to do with GDP. GDP, the gross domestic product, is essentially the dollar value of all the “Stuff” bought and sold in a country. You could also look at it as the country’s income. It’s not a perfect measure, but it can be useful. At the very least it gives me some questions to ask.
The questions that pop out to me are:
How does GDP relate to college enrollment?
How does Gasoline price relate to GDP?
Is there any relationship between latitude, longitude and GDP?
How closely are CO2 emissions and GDP linked?
How does GDP relate to college enrollment?
Let’s start on the first one,
gdp.vs.college<-ggplot(dataset, mapping = aes(y = GDP, x = Gross.tertiary.education.enrollment...., colour = Country))+
geom_point(alpha = 0.8)+
xlab("Gross College Enrollement")+
ylab("GDP(USD)")+
ggtitle("GDP and Gross College enrollment across countries")+
theme(plot.title = element_text(hjust = 0.5), legend.position = "none")+
scale_y_continuous(labels = label_dollar())
gdp.vs.college<-ggplotly(gdp.vs.college)
gdp.vs.collegeSo there’s a problem or two here. These GDP’s have a huge range. Which makes sense, some of these countries have WAY more people that others, what makes sense might be comparing the income per person instead. This is the GDP per capita. From here on out, I’ll use GDP per capita, to account for those passive population differences.
dataset<- dataset |> mutate(GDP.per.capita = round((GDP/Population), 2)) |> na.omit()
gdp.per.capita.vs.college<-ggplot(dataset, mapping = aes(y = GDP.per.capita, x = Gross.tertiary.education.enrollment...., colour = Country))+
geom_point(alpha = 0.8)+
geom_smooth(method = "lm", se = FALSE)+
ggtitle("GDP Per capita and College enrollment in various countries")+
xlab("Gross College Enrollement")+
ylab("GDP per Capita (USD)")+
theme(plot.title = element_text(hjust = 0.5), legend.position = "none")+
scale_y_continuous(labels = label_dollar())
gdp.per.capita.vs.college<-ggplotly(gdp.per.capita.vs.college)
gdp.per.capita.vs.collegeThis is a little better. While its scattered, and there are definitely outliers, you can definitely see an upward trend. It looks like generally, more college enrollment means more income per person. But it also looks like the more people in college the greater the effect. I suppose it means there’s more people with more knowledge and skills to mix and use to generate income together by collaborating.
Gas Prices and GDP
gas.vs.gdp.per.capita<-ggplot(dataset, mapping = aes(x = Gasoline.Price, y = GDP.per.capita, colour = Country))+
geom_point()+
geom_smooth()+
xlab("Gasoline Prices per litre")+
ylab("GDP per Capita (USD)")+
ggtitle('GDP per Capita and Gas Prices Around the World')+
theme(plot.title = element_text(hjust = 0.5), legend.position = "none")+
scale_y_continuous(labels = label_dollar())+
scale_x_continuous(labels = label_dollar())
gas.vs.gdp.per.capita<-ggplotly(gas.vs.gdp.per.capita)
gas.vs.gdp.per.capitaThis relationship is actually a whole lot weaker than I imagined. I wish there was electricity price or some general energy price measure instead. The relationship between gas price and GDP isn’t too strong at all. Which is fine. Sometimes the answer to a question is just “there’s nothing much to see here”.
Latitude, Longitude and GDP
cord<- dataset |> select("Latitude", "Longitude", "GDP.per.capita") |>
mutate(Latitude = abs(Latitude)) |> mutate(Longitude = abs(Longitude)) |>
na.omit()
cor.matrix<-cor(cord)
ggcorrplot(cor.matrix, type = "upper", lab = TRUE)+
labs(title = "Correlation between Latitude, Longitude and GDP per Capita")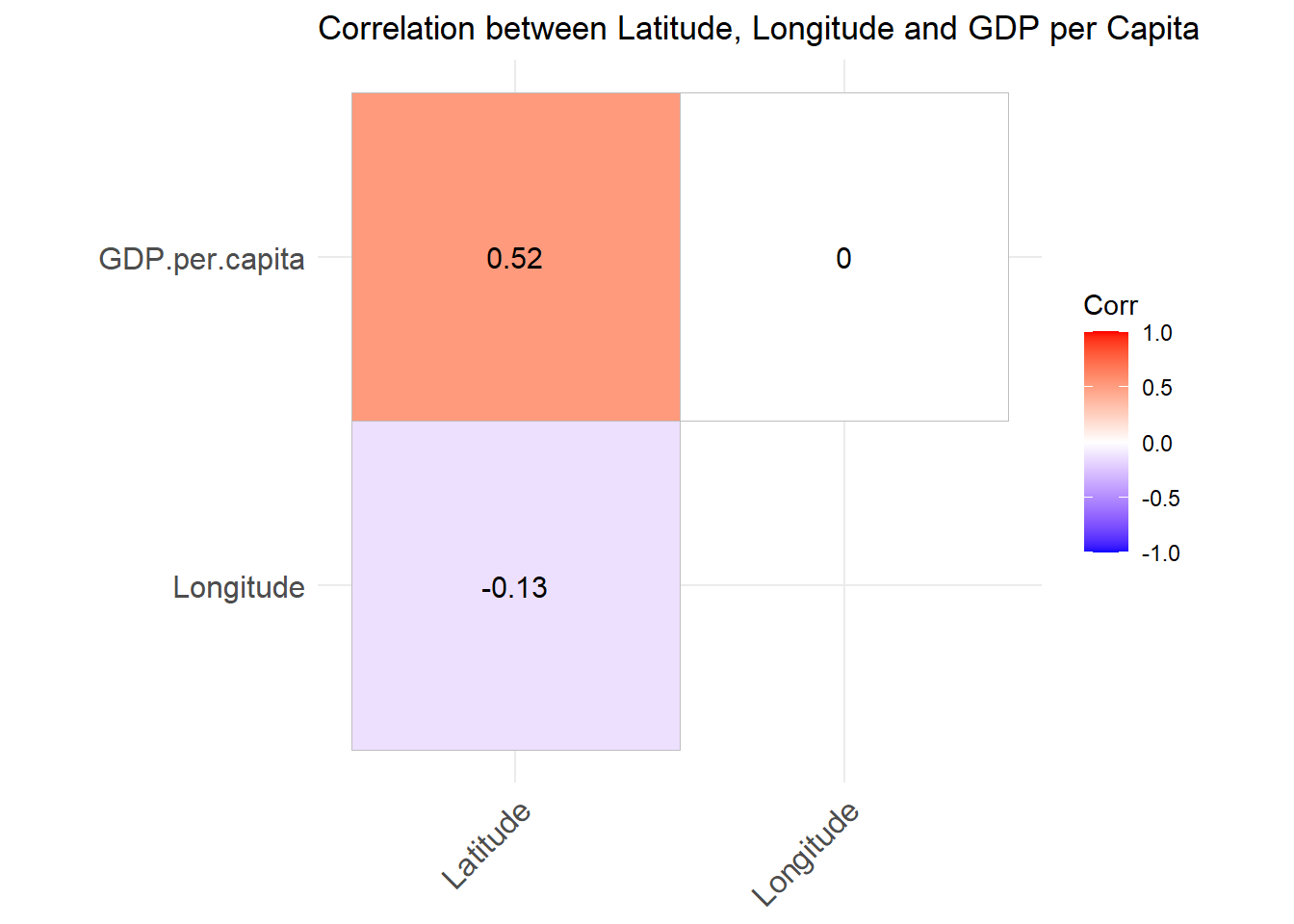
There’s not quite as much going on in this one. The GDP per capita is kind of correlated to the latitude. But I’ve seen stronger relationships. that number in red shows us that there is something there. The closer it is to 1 and redder that square, the stronger that relationship would be.
CO2 and GDP
My question here is whether the CO2 emissions of a country are strongly related to its GDP. If working to produce things for income means more CO2, then it generally follows that countries with a higher GDP should emit more.
I’ll start off looking graphically. I find its better for intuition.
CO2.vs.gdp.per.capita<-ggplot(dataset, mapping = aes(x = Co2.Emissions, y = GDP.per.capita, colour = Country))+
geom_point()+
geom_smooth()+
theme(plot.title = element_text(hjust = 0.5), legend.position = "none")+
scale_y_continuous(labels = label_dollar())+
labs(title = "GDP per Capita and CO2 Emissions for various countries")+
xlab("CO2 Emissions in tonnes")+
ylab("GDP per Capita in USD")
CO2.vs.gdp.per.capita<-ggplotly(CO2.vs.gdp.per.capita)
CO2.vs.gdp.per.capitaFrom this graph I can see a few things. Firstly, we have a few massive outliers. If you check the far right, we see China producing tons of CO2, and the US as well. Other countries are producing far less. We also have Liechtenstein, with a very high GDP per capita with pretty low emissions. For the most part though, countries are clustered towards relatively lower emissions.
There are a couple ways I can sort through this, I could remove the outliers. China’s huge emissions may just be because of its huge population. I could adjust by seeing what the CO2 per person is.
dataset <- dataset |> mutate(co2.per.capita = Co2.Emissions/Population) |> na.omit()
co2.gdp.plot<-dataset |> ggplot(mapping = aes(x = co2.per.capita, y = GDP.per.capita, colour = Country))+
geom_point()+
geom_smooth()+
theme(plot.title = element_text(hjust = 0.5), legend.position = "none")+
scale_y_continuous(labels = label_dollar())+
labs(title = "GDP per Capita and CO2 Emissions per capita for various countries")+
xlab("CO2 Emissions per capita in tonnes")+
ylab("GDP per Capita in USD")
co2.gdp.plot<-ggplotly(co2.gdp.plot)
co2.gdp.plotNow we’re seeing a little more detail. Correcting for the huge difference in populations made a difference. We see a general upward trend, but there are still plenty of outliers, and the relationship could be a lot stronger. There are ways to model and get more info in this relationships, but that’s a topic for later.
General Correlation
So, I’ll admit. This should be one of the first steps I took. In trying to put these posts out relatively fast and consistently, I may have rushed the process. There’s a life lesson in there somewhere. I could move this to the top, but I think I’ll leave it here. It will show my actual thought process as I went through this analysis, and be a reminder to go through more methodically next time. In fact, I’ll follow up with this exact data at some point in the future
This is a correlation matrix. I’ve used them before in my previous post here and I’m kind of fond of them. Essentially, it’s a graphical way to see how closely related two variables or properties or attributes are. It’s really applicable for numeric data, but on a dataset like this, doing one is invaluable.
numerics<-dataset |> select_if(is.numeric) |> na.omit()
numerics<-cor(numerics)
general.cor.plot<-ggcorrplot(numerics, hc.order = TRUE, type = "upper")+
theme(axis.text.x = element_blank(), axis.text.y = element_blank())+
labs(title = "General Correlations")+
theme(plot.title = element_text(hjust = 0.5))
general.cor.plot<-ggplotly(general.cor.plot)
general.cor.plotThe “redder” the numbers, the more strongly related the variables are. For example two variables which are exactly the same would show up as the reddest. On the flip side, if two variables are related strongly, in opposite directions, they would show up the “Bluest”. These are “Negatively correlated.”
Because of how much data there is, I’ve opted to remove the labels and make the graph interactive. If you hover your mouse over a square, you should see the variables that are being compared.
You can see 3 clusters of red, showing areas of strongly related variables, and one major blue cluster showing variables which are negatively correlated. And from this there’s so many questions. Each of those clusters represent sets of relationships we could ask about. In fact, you can hover your mouse over the squares to see for yourself.
Just hovering the mouse over each cluster:
The bottom red cluster has to do with relationships with “Birth stuff” like birth and fertility rates
The middle red cluster has to do with “Population size stuff”, including urban population, army size ect.
The top red cluster is more “Income and demographics stuff”, like minimum wage and life expectancy.
The blue cluster is “Birth Stuff’, connecting birth stuff to income and life expectancy
So you’ve seen my process at the moment, and some of the mistakes I’ve made. One day soon, you’ll see me re-attempt. Until next time, walk good.
sessionInfo()R version 4.4.2 (2024-10-31 ucrt)
Platform: x86_64-w64-mingw32/x64
Running under: Windows 11 x64 (build 26100)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.utf8
[2] LC_CTYPE=English_United States.utf8
[3] LC_MONETARY=English_United States.utf8
[4] LC_NUMERIC=C
[5] LC_TIME=English_United States.utf8
time zone: America/Bogota
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] ggcorrplot_0.1.4.1 corrplot_0.95 scales_1.3.0 plotly_4.10.4
[5] lubridate_1.9.4 forcats_1.0.0 stringr_1.5.1 dplyr_1.1.4
[9] purrr_1.0.2 readr_2.1.5 tidyr_1.3.1 tibble_3.2.1
[13] ggplot2_3.5.1 tidyverse_2.0.0
loaded via a namespace (and not attached):
[1] generics_0.1.3 stringi_1.8.4 hms_1.1.3 digest_0.6.37
[5] magrittr_2.0.3 evaluate_1.0.3 grid_4.4.2 timechange_0.3.0
[9] fastmap_1.2.0 plyr_1.8.9 jsonlite_1.8.9 httr_1.4.7
[13] crosstalk_1.2.1 viridisLite_0.4.2 lazyeval_0.2.2 cli_3.6.3
[17] rlang_1.1.5 munsell_0.5.1 withr_3.0.2 yaml_2.3.10
[21] tools_4.4.2 reshape2_1.4.4 tzdb_0.4.0 colorspace_2.1-1
[25] vctrs_0.6.5 R6_2.5.1 lifecycle_1.0.4 htmlwidgets_1.6.4
[29] pkgconfig_2.0.3 pillar_1.10.1 gtable_0.3.6 Rcpp_1.0.14
[33] glue_1.8.0 data.table_1.16.4 xfun_0.50 tidyselect_1.2.1
[37] rstudioapi_0.17.1 knitr_1.49 farver_2.1.2 htmltools_0.5.8.1
[41] rmarkdown_2.29 labeling_0.4.3 compiler_4.4.2